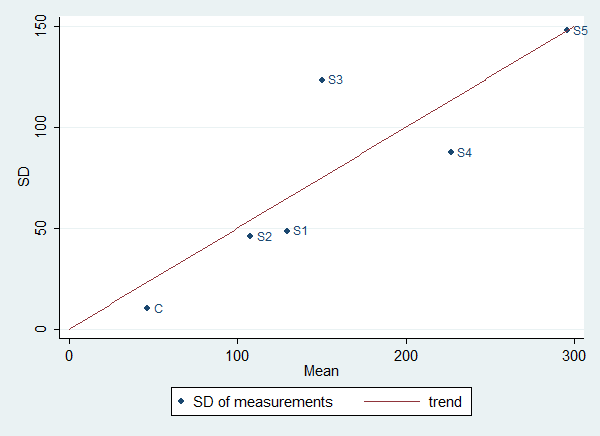
Tengo el siguiente conjunto de datos (valores triplicados de 5 mediciones independientes y valores duplicados de un control):
Muestra 1 Muestra 2 Muestra 3 Muestra 4 Muestra 5 C
181.8 58.2 288.9 273.2 290.9 53.9
120.3 116.8 108.9 281.3 446 39.6
86.1 148.5 52.9 126 150.3Las seis condiciones son la producción independiente de un producto químico en seis microorganismos diferentes.
Mi objetivo era determinar si la producción del químico es significativamente mayor en las Muestras 1 - 5 que en C (control).
Al principio, realicé la media, la desviación estándar y la prueba t (una cola). Aunque las barras de error de la desviación estándar son grandes, dos de las muestras tienen valores medios que son significativamente más altos que el de C.
Decidí realizar la mediana y la prueba de Wilcoxon-Mann-Whitney debido a mi preocupación por el tamaño de mis datos y las altas variaciones en las réplicas. Sin embargo, me sorprendió que la mediana y las pruebas de Wilcoxon-Mann-Whitney no revelaron resultados estadísticamente significativos.
Estaré feliz si alguien pudiera aconsejarme sobre la mejor manera de analizar este pequeño conjunto de datos.