La función de costo de una red neuronal es en general, ni convexa ni cóncava. Esto significa que la matriz de todas las segundas derivadas parciales (Hesse), no es ni positivo semidefinite, ni negativo semidefinite. Desde la segunda derivada es una matriz, es posible que no es ni uno ni el otro.
Para hacer este análoga a la de una variable funciones, se podría decir que la función de costo es ni la forma de la gráfica de $x^2$ ni como la gráfica de $-x^2$. Otro ejemplo de no-convexo, no cóncava función es$\sin(x)$$\mathbb{R}$. Una de las diferencias más sorprendentes es que el $\pm x^2$ tiene sólo un extremo, mientras que el $\sin$ tiene infinidad de máximos y mínimos.
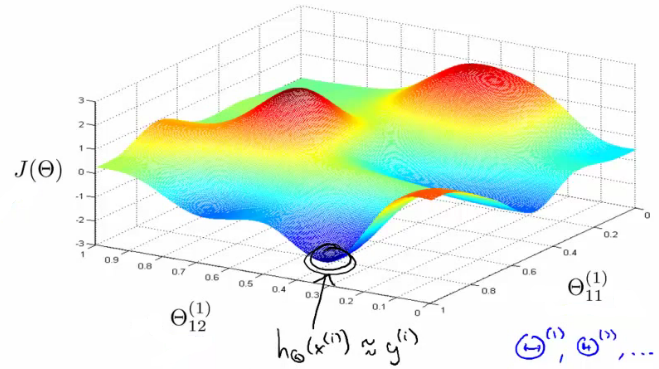
Cómo se relaciona esto con nuestra red neuronal? Una función de coste $J(W,b)$ tiene también una serie de máximos y mínimos locales, como se puede ver en esta foto, por ejemplo.
El hecho de que $J$ tiene múltiples mínimos también se puede interpretar de una forma agradable. En cada capa, se usan varios nodos que se asignan a distintos parámetros para que la función de costo pequeño. Excepto para los valores de los parámetros, estos nodos son los mismos. Así que usted puede intercambiar los parámetros del primer nodo en una capa con los del segundo nodo en la misma capa, y la contabilidad para que este cambio en las capas siguientes. Se acabaría con un conjunto diferente de parámetros, pero el valor de la función de costo no puede ser distinguido por (básicamente se acaba de mudar a un nodo a otro lugar, pero mantiene todas las entradas/salidas de la misma).



{kind=link}