
Tengo algunas miles baldosas TIF y necesito extraer polígonos de la cobertura real de datos desde dentro de estos TIFs (ver abajo para la imagen que muestra cómo se ve la cobertura). La geometría resultante será cargada en una tabla de Postgres.
Debido a la cantidad de TIFs, y al hecho de que el conjunto de datos será actualizado regularmente, necesito que el proceso sea lo más eficiente y automatizado posible.
He intentado gdal_polygonize.py, pero esto me da un resultado como este:
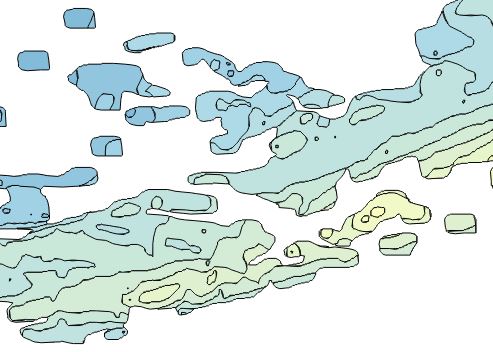
Luego tendría que 'disolver' estos polígonos, o ejecutar ST_Union con PostGIS para obtener el resultado que quiero, que se ve así:
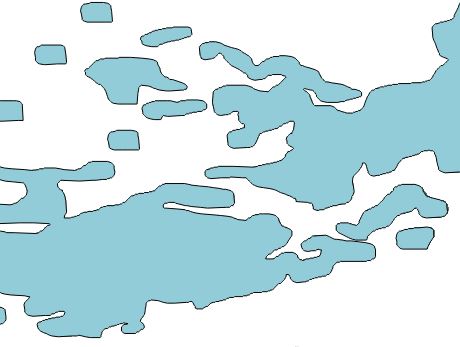
La disolución es muy lenta, y parece innecesaria cuando seguramente debe haber una forma de omitir el resultado de múltiples polígonos de gdal_polygonize.
¿Alguien tiene alguna idea de cómo podría hacerlo en un solo paso, o simplemente hacer el proceso más rápido/más eficiente?


0 votos
Por favor, echa un vistazo a mi respuesta. Es más una solución temporal y no sé si podría adaptarse bien a tu caso.