Estás confundiendo dos tipos de términos de "error". Wikipedia tiene un artículo dedicado a esta distinción entre errores y residuos.
En una regresión OLS, los residuos (tus estimaciones del término de error o perturbación) $\hat \varepsilon$ están garantizados de ser no correlacionados con las variables predictoras, asumiendo que la regresión contiene un término de intercepción.
Pero los "verdaderos" errores $\varepsilon$ podrían estar correlacionados con ellos, y esto es lo que cuenta como endogeneidad.
Para mantener las cosas simples, considera el modelo de regresión (que podrías ver descrito como el "proceso generador de datos" subyacente o "DGP", el modelo teórico que asumimos para generar el valor de $y$):
$$y_i = \beta_1 + \beta_2 x_i + \varepsilon_i$$
No hay ninguna razón, en principio, por la cual $x$ no pueda estar correlacionado con $\varepsilon$ en nuestro modelo, sin importar cuánto preferiríamos que no violara las suposiciones estándar de OLS de esta manera. Por ejemplo, podría ser que $y$ dependa de otra variable que ha sido omitida de nuestro modelo, y esto se ha incorporado en el término de perturbación (el $\varepsilon$ es donde agrupamos todas las cosas aparte de $x$ que afectan a $y$). Si esta variable omitida también está correlacionada con $x$, entonces $\varepsilon$ a su vez estará correlacionado con $x$ y tendremos endogeneidad (en particular, sesgo por variable omitida).
Cuando estimas tu modelo de regresión en los datos disponibles, obtenemos
$$y_i = \hat \beta_1 + \hat \beta_2 x_i + \hat \varepsilon_i$$
Debido a la forma en que funciona OLS*, los residuos $\hat \varepsilon$ estarán no correlacionados con $x$. Pero eso no significa que hayamos evitado la endogeneidad, simplemente significa que no podemos detectarlo analizando la correlación entre $\hat \varepsilon$ y $x$, que será (hasta error numérico) cero. Y debido a que las suposiciones de OLS han sido violadas, ya no tenemos garantizadas las propiedades agradables, como la imparcialidad, que disfrutamos tanto en OLS. Nuestra estimación $\hat \beta_2$ estará sesgada.
$(*)$ El hecho de que $\hat \varepsilon$ esté no correlacionado con $x$ sigue inmediatamente de las "ecuaciones normales" que usamos para elegir nuestras mejores estimaciones para los coeficientes.
Si no estás acostumbrado al entorno matricial, y me adhiero al modelo bivariado utilizado en mi ejemplo anterior, entonces la suma de los residuos al cuadrado es $S(b_1, b_2) = \sum_{i=1}^n \varepsilon_i^2 = \sum_{i=1}^n (y_i-b_1 - b_2 x_i)^2$ y para encontrar el óptimo $b_1 = \hat \beta_1$ y $b_2 = \hat \beta_2$ que minimizan esto encontramos las ecuaciones normales, primero la condición de primer orden para la intercepción estimada:
$$\frac{\partial S}{\partial b_1} = \sum_{i=1}^n -2(y_i-b_1 - b_2 x_i) = -2 \sum_{i=1}^n \hat \varepsilon_i = 0$$
lo que muestra que la suma (y por lo tanto el promedio) de los residuos es cero, por lo que la fórmula para la covarianza entre $\hat \varepsilon$ y cualquier variable $x$ se reduce a $\frac{1}{n-1} \sum_{i=1}^n x_i \hat \varepsilon_i$. Vemos que esto es cero considerando la condición de primer orden para la pendiente estimada, que es
$$\frac{\partial S}{\partial b_2} = \sum_{i=1}^n -2 x_i (y_i-b_1 - b_2 x_i) = -2 \sum_{i=1}^n x_i \hat \varepsilon_i = 0$$
Si estás acostumbrado a trabajar con matrices, podemos generalizar esto a la regresión múltiple definiendo $S(b) = \varepsilon' \varepsilon = (y-Xb)'(y-Xb)$; la condición de primer orden para minimizar $S(b)$ en el óptimo $b = \hat \beta$ es:
$$\frac{dS}{db}(\hat\beta) = \frac{d}{db}\bigg(y'y - b'X'y - y'Xb + b'X'Xb\bigg)\bigg|_{b=\hat\beta} = -2X'y + 2X'X\hat\beta = -2X'(y - X\hat\beta) = -2X'\hat \varepsilon = 0$$
Esto implica que cada fila de $X'$, y por lo tanto cada columna de $X$, es ortogonal a $\hat \varepsilon$. Luego, si la matriz de diseño $X$ tiene una columna de unos (lo cual sucede si tu modelo tiene un término de intercepción), debemos tener $\sum_{i=1}^n \hat \varepsilon_i = 0$ para que los residuos tengan suma y promedio cero. La covarianza entre $\hat \varepsilon$ y cualquier variable $x$ es nuevamente $\frac{1}{n-1} \sum_{i=1}^n x_i \hat \varepsilon_i$ y para cualquier variable $x$ incluida en nuestro modelo sabemos que esta suma es cero, porque $\hat \varepsilon$ es ortogonal a cada columna de la matriz de diseño. Por lo tanto, no hay covarianza, y no hay correlación, entre $\hat \varepsilon$ y cualquier variable predictora $x$.
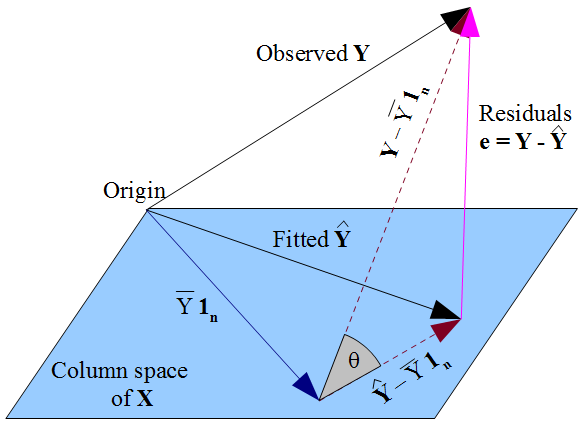
Si prefieres una visión más geométrica de las cosas, nuestro deseo de que $\hat y$ se encuentre lo más cerca posible de $y$ de una manera tipo pitagórica, y el hecho de que $\hat y$ esté restringido al espacio de columnas de la matriz de diseño $X$, dictan que $\hat y$ debería ser la proyección ortogonal del $y$ observado en ese espacio de columnas. Por lo tanto, el vector de residuos $\hat \varepsilon = y - \hat y$ es ortogonal a cada columna de $X$, incluyendo el vector de unos $\mathbf{1_n}$ si se incluye un término de intercepción en el modelo. Como antes, esto implica que la suma de los residuos es cero, por lo que la ortogonalidad del vector residual con las otras columnas de $X$ asegura que no está correlacionado con ninguno de esos predictores.
![Vectores en el espacio sujeto a regresión múltiple]()
Pero nada de lo que hemos hecho aquí dice nada sobre los verdaderos errores $\varepsilon$. Suponiendo que hay un término de intercepción en nuestro modelo, los residuos $\hat \varepsilon$ solo están no correlacionados con $x$ como consecuencia matemática de la manera en que elegimos estimar los coeficientes de regresión $\hat \beta$. La forma en que seleccionamos nuestros $\hat \beta$ afecta nuestras valores predichos $\hat y$ y por lo tanto nuestros residuos $\hat \varepsilon = y - \hat y$. Si elegimos $\hat \beta$ por OLS, debemos resolver las ecuaciones normales y estas garantizan que nuestros residuos estimados $\hat \varepsilon$ estén no correlacionados con $x$. Nuestra elección de $\hat \beta$ afecta a $\hat y$ pero no a $\mathbb{E}(y)$ y por lo tanto no impone condiciones sobre los errores verdaderos $\varepsilon = y - \mathbb{E}(y)$. Sería un error pensar que $\hat \varepsilon$ ha "heredado" de alguna manera su falta de correlación con $x$ de la suposición de OLS de que $\varepsilon$ debería estar no correlacionado con $x$. La falta de correlación surge de las ecuaciones normales.



11 votos
El beta de regresión se elige de tal manera que el residual sea ortogonal al espacio de columnas de la matriz de diseño. ¡Y esto puede dar una horrible estimación del verdadero beta si el término de error no es ortogonal al espacio de columnas de la matriz de diseño! (es decir, si su modelo no cumple con las suposiciones necesarias para estimar consistentemente los coeficientes por regresión).
3 votos
La ortogonalidad del término de error y el espacio de columnas de la matriz de diseño no es una propiedad de tu método de estimación (por ejemplo, regresión por mínimos cuadrados ordinarios), es una propiedad del modelo (por ejemplo, $y_i = a + bx_i + \epsilon_i$).
0 votos
Creo que tu edición debería ser una nueva pregunta porque parece que has cambiado sustancialmente lo que estás pidiendo. Siempre puedes enlazar de vuelta a esta. (Creo que también necesitas expresarlo mejor, cuando escribes "cuál sería el efecto" entonces no está claro el efecto de qué?) Ten en cuenta que hacer una nueva pregunta generalmente atrae más atención, lo cual sería una ventaja para ti en lugar de editar una existente.