La elección de n = 30 como límite entre muestras pequeñas y grandes es solo una regla general. Hay una gran cantidad de libros que citan (alrededor de) este valor, por ejemplo, Hogg y Tanis en Probabilidad e Inferencia Estadística (7a edición) dicen "mayor que 25 o 30".
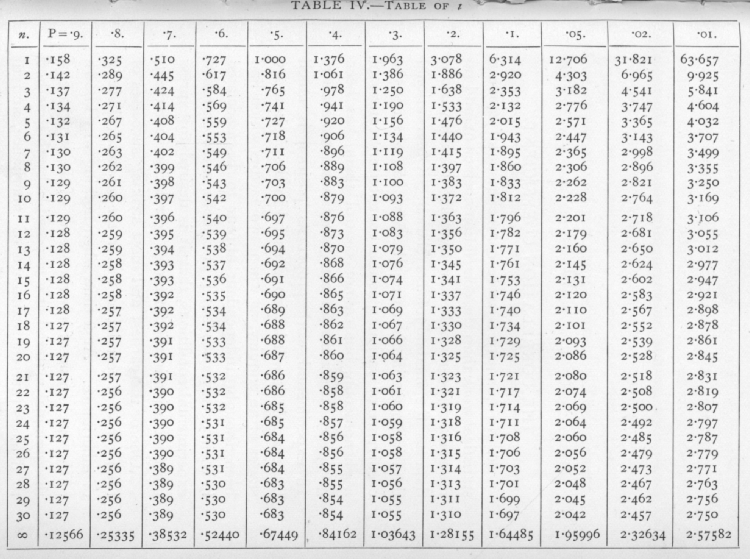
Dicho esto, la historia que me contaron fue que la única razón por la que se consideraba que 30 era un buen límite era porque hacía que las bonitas tablas de Student de t en la parte posterior de los libros encajaran perfectamente en una página. Además, los valores críticos (entre t de Student y Normal) solo difieren aproximadamente hasta 0.25, de df = 30 a df = infinito. Para el cálculo manual, la diferencia realmente no importaba.
Hoy en día es fácil calcular valores críticos con precisión hasta 15 decimales. Además, tenemos métodos de remuestreo y permutación para los cuales ni siquiera estamos limitados a distribuciones poblacionales paramétricas.
En la práctica, nunca confío en n = 30. Grafica los datos. Superpone una distribución normal, si lo deseas. Evalúa visualmente si es adecuada una aproximación normal (y pregúntate si realmente se necesita una aproximación). Si estás generando muestras para investigación y se requiere una aproximación, genera un tamaño de muestra suficiente para que la aproximación sea tan cercana como se desee (o tan cercana como sea factible computacionalmente).



4 votos
Sin referencia al número de parámetros que intenta estimar, o equivalentemente al tipo de modelo con el que está trabajando, parece bastante difícil darle una respuesta clara.
8 votos
La aceptación de n=30 como límite entre muestras pequeñas y grandes no está bien respaldada por ninguna técnica estadística.
3 votos
Una referencia que puede citar ahora (a partir de 2013) para demostrar que 30 unidades no necesariamente son suficientes, y demostrando que no puede haber una referencia correcta que respalde su afirmación, aparece aquí en CV en stats.stackexchange.com/questions/69898.