Estoy trabajando en un conjunto de datos que son bastante inusuales de las siguientes maneras:
- No tiene solo texto en lenguaje natural, tiene texto como nombres de usuario, incluso fragmentos de código, etc.
- Tamaño de vocabulario (tokens únicos) inusualmente grande (2M) para un conjunto de documentos de 750K y aproximadamente 19M de tokens.
Todos los aspectos del conjunto de datos son importantes y deben incluirse en el entrenamiento, es decir, los nombres de usuario, los fragmentos de código, etc.
Entrené una Asignación Latente de Dirichlet (LDA) después de la tokenización, eliminación de palabras de parada y derivación. El tamaño del conjunto de entrenamiento es de 720K, con aproximadamente 16M de tokens. Entrené para 200 y 300 temas y 50 y 100 pasadas sobre los datos de entrenamiento.
Estaba probando en el conjunto de pruebas para ver una distribución de los primeros 5 temas más probables de cada documento en el conjunto de pruebas.
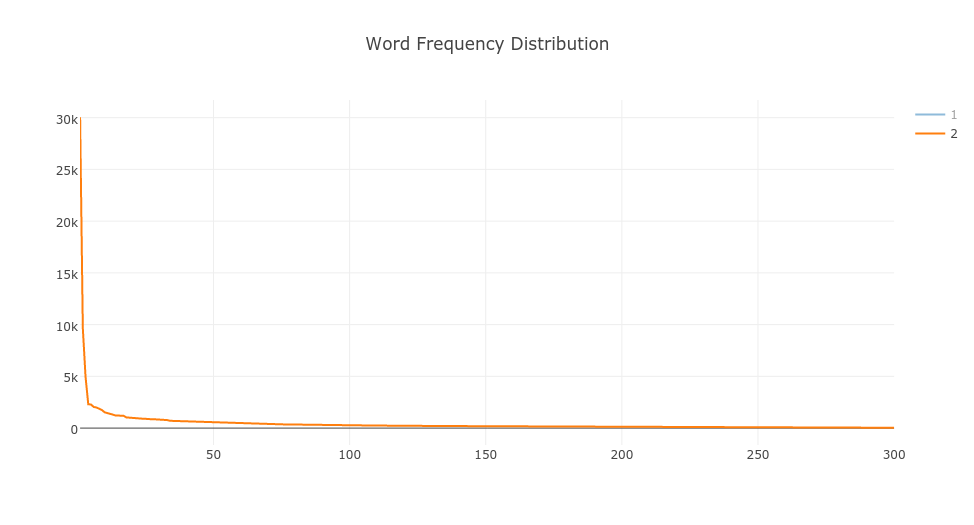
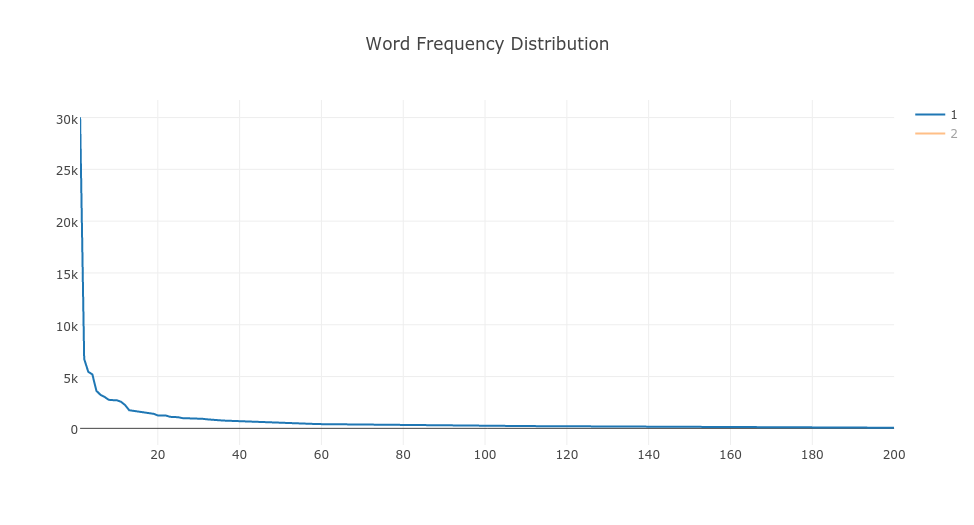
Lo que descubrí fue que está siguiendo la ley de Zip para tanto 200 como 300 temas.
¿Puede alguien explicar por qué está ocurriendo esto? ¿Menos entrenamiento o más entrenamiento o cuál podría ser la razón?
Aquí está la distribución de 200 temas (naranja) y 300 temas (azul). (Perdón por el título incorrecto.) Los gráficos se trazan extrayendo los 5 temas principales de cada documento y luego contando el valor para cada tema, es decir, frecuencia de tema en el conjunto de pruebas y trazando la frecuencia en orden decreciente.