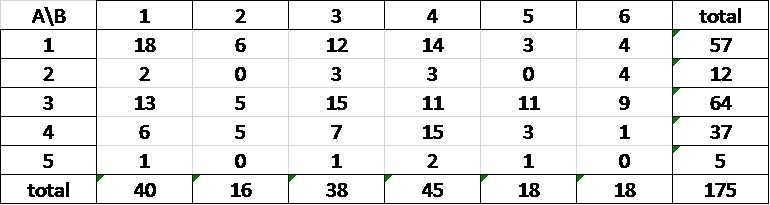
Tengo un conjunto de datos n=175 y para 2 agrupaciones diferentes (A y B) tengo 5 y 6 grupos. La tabla de similitud de las agrupaciones está a continuación. Primero calculé el Índice de Rand tanto manualmente con Excel como con la función "cluster_similarity" en R y obtuve 63,4%. Luego calculé el Índice de Rand Ajustado tanto con Excel como con la función "adjustedRandIndex" en R. Obtuve 0,003, ni siquiera %3. ¿Por qué esta gran diferencia? Estoy muy confundido, estaba planeando usar el Índice de Rand para mi trabajo, pero tengo miedo de tener que usar el ajustado. Hay algunos ceros y unos en la tabla, tal vez esos sean el problema.