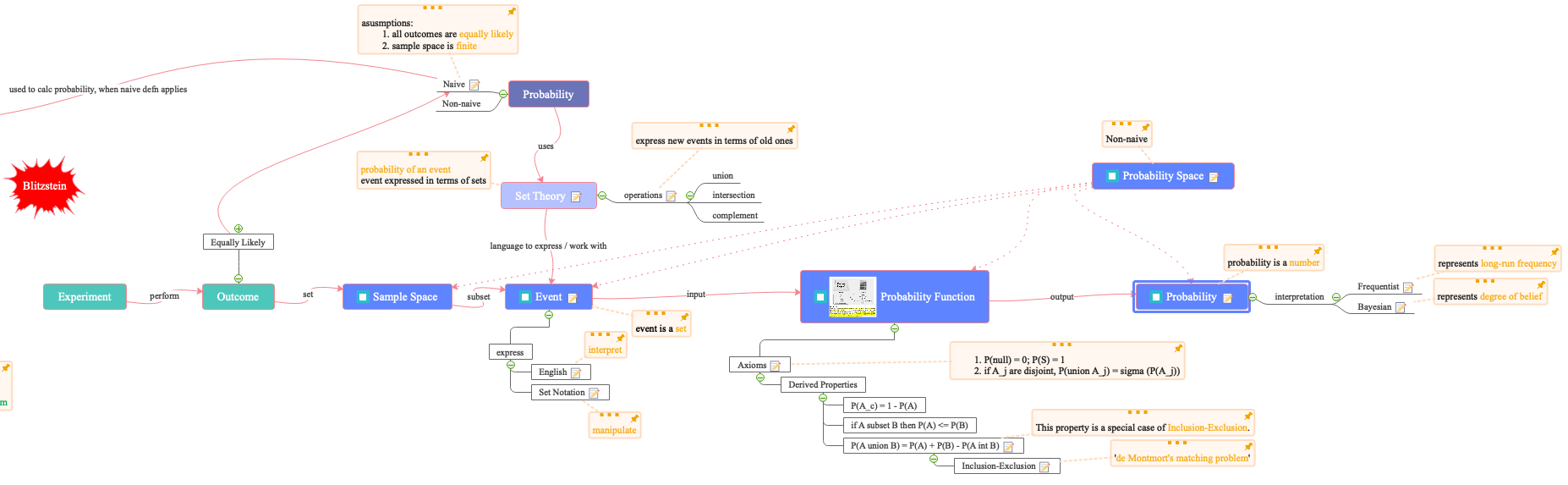
Un modelo estadístico es una tupla que contiene un espacio muestral S y un conjunto de distribuciones P en ese espacio muestral. Estoy obteniendo esta definición de wikipedia, "What is a Statistical Model" de McCullagh, y "All of Statistics" de Wasserman.
Supongamos que tenemos un conjunto de datos de altura y edad para un grupo de árboles, y queremos crear un modelo estadístico para predecir la altura a partir de la edad.
¿Es el espacio muestral:
- R (el conjunto de posibles alturas de un árbol)
- Rn (el producto de los conjuntos de alturas posibles para cada uno de los n árboles en nuestros datos)
- R2 (el conjunto de alturas y edades posibles de un árbol)
Después de pensarlo por un tiempo, ninguna de estas opciones parece funcionar completamente.
(1) parece razonable al principio, pero no puede ser correcto, porque no hay ningún mecanismo para condicionar la distribución a la edad, por lo que básicamente lo mejor que podríamos hacer es ajustar una única distribución a todas las alturas. Además, esto parece evitar que se pueda definir cualquier modelo que no asuma datos i.i.d.
(2) resuelve estos problemas, ya que podrías definir una distribución conjunta completa sobre todas las alturas. Sin embargo, suena extremadamente extraño porque tu modelo está básicamente "fijado" por el tamaño de los datos. Si quisieras agregar un nuevo punto de datos, o predecir la altura a partir de la edad de un nuevo árbol, necesitarías crear un modelo completamente nuevo con un espacio muestral Rn+1 y luego "copiar" los parámetros, lo cual me parece bastante extraño.
Otra razón por la que esto no parece correcto es que en las notas de Larry Wasserman sobre modelos estadísticos y estadísticas suficientes, él menciona que cualquier función de x1,...,xmp(x;) (donde p es un elemento de P) es una estadística, como por ejemplo la mediana. Esto sugiere fuertemente (1) sobre (2), porque no tendría mucho sentido muestrear alturas para cada uno de los n árboles, m veces diferentes, y luego tomar la mediana (¿qué significa eso realmente?).
(3) esto nos permite modelar la distribución conjunta de edad y altura, y luego condicionar en la edad posteriormente, por lo que parece resolver el problema sin caer en las rarezas de (2). Sin embargo, sigue siendo muy extraño que estemos obligados a modelar una distribución conjunta, incluso si queremos un modelo puramente discriminativo. Supongo que uno podría simplemente especificar p(altura, edad) = p(altura|edad)p(edad), y luego elegir literalmente cualquier distribución para la edad y ignorarla, pero esto apenas sería sensato.
Esta es una pregunta muy básica, pero he estado atascado por un tiempo, así que siento que debo haber entendido mal algo en algún lugar...