
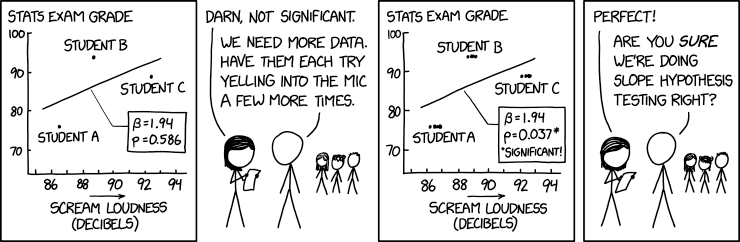
 Prueba de la hipótesis de la pendiente (Randall Munroe, xkcd )
Prueba de la hipótesis de la pendiente (Randall Munroe, xkcd )
El problema de este cómic es, obviamente, que las "mediciones" no son independientes, lo que viola un supuesto clave para calcular valores p válidos. Pero también veo un posible problema en el hecho de que la variable dependiente "nota" sea constante para cada alumno.
¿Cuál es la forma correcta de analizar estos datos?
He extraído los datos y he probado un modelo de efectos aleatorios, pero no estaba claro cómo especificar la estructura del modelo. Hasta ahora he obtenido los mejores resultados utilizando el método lm.cluster de la función miceadds y especificando cada estudiante como su propio clúster. Aun así, obtengo un valor p de 0,12, que dista mucho del valor p original de 0,586.

Ejemplo reproducible:
pane3 <-
structure(list(loudness = c(86.23265220830784, 86.525433974655584,
86.70530770034479, 86.885181426033995, 88.689627893786295, 88.892405630102843,
89.049912682657435, 89.207285400838856, 92.147394659462378, 92.417541083929137,
92.575182470856902, 92.709919847157337), grade = c(75.96108780990194,
76.148932041733218, 76.064749167873202, 75.980566294013173, 93.944878128871437,
94.130035673239107, 94.134737376300436, 94.049882830574518, 89.122721912921492,
89.220338224099606, 89.314596175948196, 89.139513709569087),
student = c("A", "A", "A", "A", "B", "B", "B", "B", "C",
"C", "C", "C")), row.names = c(NA, -12L), class = c("spec_tbl_df",
"tbl_df", "tbl", "data.frame"), spec = structure(list(cols = list(
loudness = structure(list(), class = c("collector_double",
"collector")), grade = structure(list(), class = c("collector_double",
"collector"))), default = structure(list(), class = c("collector_guess",
"collector")), delim = ","), class = "col_spec"))
ggplot(pane3, aes(x = loudness, y = grade)) +
geom_point() +
geom_smooth(method = "lm")
summary(lm(grade ~ loudness, pane3))
library(lme4)
summary(lmer(grade ~ loudness + (1 | student), pane3))
library(miceadds)
summary(lm.cluster(data = pane3, formula = grade ~ loudness, cluster = "student"))

