Dentro de los campos del procesamiento de señales adaptativo/aprendizaje automático, deep learning (DL) es una metodología particular en la cual podemos entrenar a las máquinas para que generen representaciones complejas.
Generalmente, tendrán una formulación que puede mapear su entrada $\mathbf{x}$, hasta el objetivo deseado, $\mathbf{y}$, a través de una serie de operaciones apiladas jerárquicamente (aquí es de donde proviene lo 'profundo'). Estas operaciones suelen ser operaciones/proyecciones lineales ($W_i$), seguidas de no linealidades ($f_i$), de la siguiente manera:
$$ \mathbf{y} = f_N(...f_2(f_1(\mathbf{x}^T\mathbf{W}_1)\mathbf{W}_2)...\mathbf{W}_N) $$
Ahora dentro del DL, hay muchas arquitecturas diferentes: Una de esas arquitecturas es conocida como una red neuronal convolucional (CNN). Otra arquitectura es conocida como un perceptrón multicapa (MLP), etc. Diferentes arquitecturas se prestan para solucionar diferentes tipos de problemas.
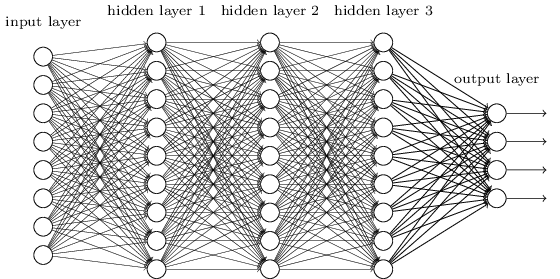
Un MLP es quizás uno de los tipos de arquitecturas de DL más tradicionales que se pueden encontrar, y en este caso cada elemento de una capa previa está conectado con cada elemento de la capa siguiente. Se ve así:
![enter image description here]()
En los MLPs, las matrices $\mathbf{W}_i$ codifican la transformación de una capa a otra. (A través de una multiplicación de matrices). Por ejemplo, si tienes 10 neuronas en una capa conectadas a 20 neuronas en la siguiente, entonces tendrás una matriz $\mathbf{W} \in R^{10 \text{x} 20}$, que mapeará una entrada $\mathbf{v} \in R^{10 \text{x} 1}$ a una salida $\mathbf{u} \in R^{1 \text{x} 20}$, a través de: $\mathbf{u} = \mathbf{v}^T \mathbf{W}$. Cada columna en $\mathbf{W}$ codifica todas las conexiones desde todos los elementos de una capa, hacia uno de los elementos de la siguiente capa.
Los MLPs cayeron en desuso entonces, en parte porque eran difíciles de entrenar. Aunque hay muchas razones para esa dificultad, una de ellas también fue que sus conexiones densas no les permitían escalar fácilmente para varios problemas de visión por computadora. En otras palabras, no tenían incorporada la equivarianza a la traslación. Esto significa que si había una señal en una parte de la imagen a la que necesitaban ser sensibles, deberían aprender nuevamente a ser sensibles a ella si esa señal se movía. Esto desperdiciaba la capacidad de la red y hacía que el entrenamiento fuera difícil.
¡Aquí es donde entran las CNNs! Así es como se ven:
![enter image description here]()
Las CNNs resolvieron el problema de traslación de señal, porque convolucionaban cada señal de entrada con un detector (núcleo) y así eran sensibles a la misma característica, pero esta vez en todas partes. En ese caso, nuestra ecuación sigue viéndose igual, pero las matrices de pesos $\mathbf{W_i}$ son en realidad matrices toeplitz convolucionales. Aunque las matemáticas son las mismas.
Es común ver que "CNNs" se refieran a redes donde tenemos capas convolucionales a lo largo de toda la red, y MLPs al final, por lo que este es un detalle a tener en cuenta.





0 votos
Dime cuál es la diferencia exacta entre el aprendizaje profundo y la red neuronal convolucional, estoy algo confundido en estos dos temas.