
Recientemente había hecho un análisis de los efectos de la reputación en los upvotes (ver el blog-post ), y posteriormente tuve algunas preguntas sobre análisis y gráficos posiblemente más esclarecedores (o más apropiados).
Así que algunas preguntas (y siéntanse libres de responder a alguien en particular e ignorar a los demás):
-
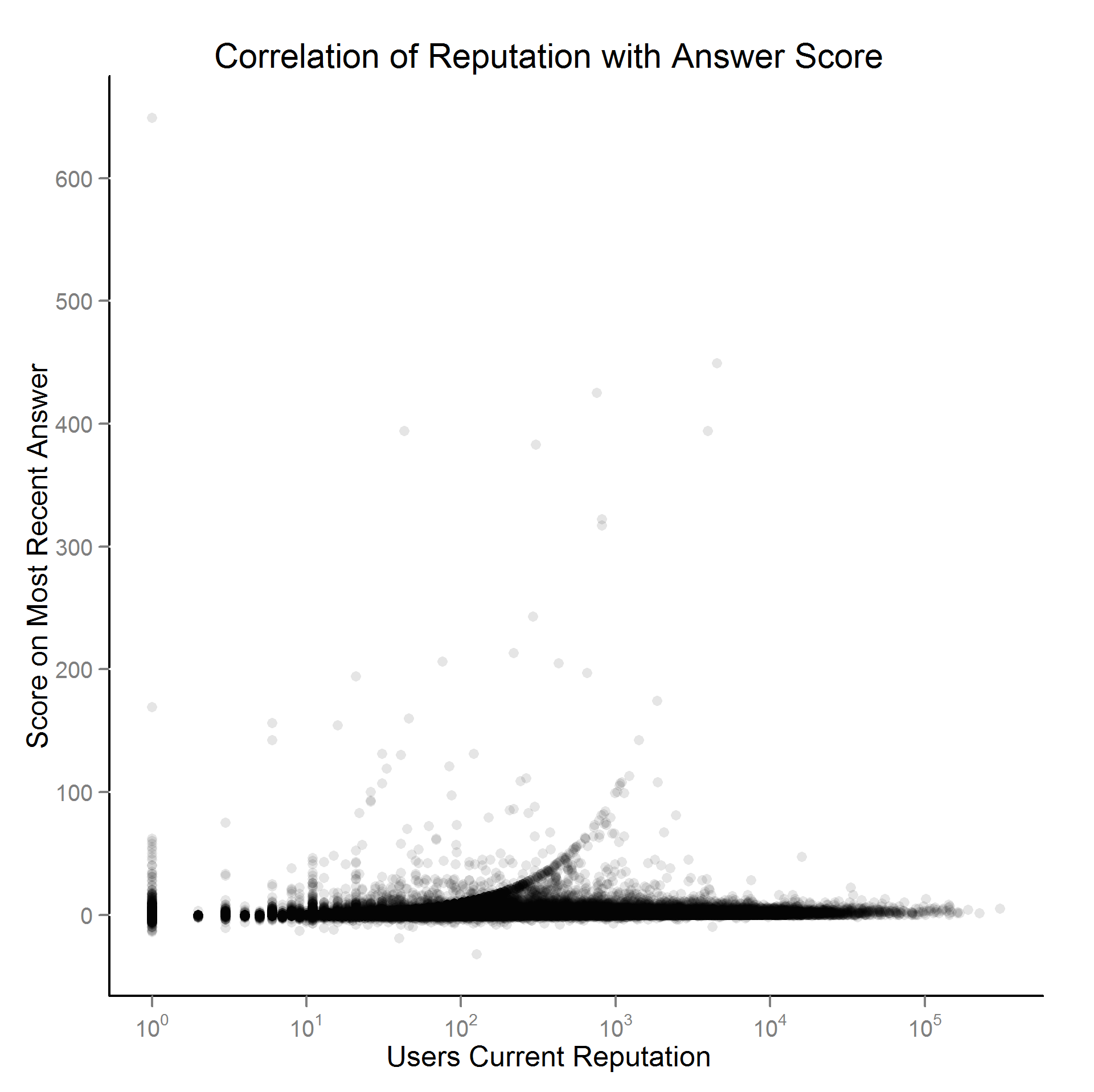
En su encarnación actual, no me refería a centrar el número de puesto. Creo que lo que esto hace es dar la falsa apariencia de una correlación negativa en el gráfico de dispersión, ya que hay más mensajes hacia el extremo inferior del número de mensajes (se ve que esto no sucede en el panel de Jon Skeet, sólo en el panel de usuarios mortales). ¿Es inapropiado no centrar el número de mensajes (ya que me refiero a centrar la puntuación media por usuario)?
-
Debería ser obvio, a partir de los gráficos, que la puntuación está muy sesgada hacia la derecha (y el centrado de la media no cambió nada). Al ajustar una línea de regresión, ajusté tanto los modelos lineales como un modelo que utiliza los errores de Huber-White sandwhich (a través de
rlmen el paquete MASS R ) y no supuso ninguna diferencia en las estimaciones de la pendiente. ¿Debería haber considerado una transformación de los datos en lugar de una regresión robusta? Tenga en cuenta que cualquier transformación tendría que tener en cuenta la posibilidad de 0 y las puntuaciones negativas. ¿O debería haber utilizado algún otro tipo de modelo para datos de recuento en lugar de MCO? -
Creo que los dos últimos gráficos, en general, podrían mejorarse (y está relacionado con la mejora de las estrategias de modelado también). En mi (harta) opinión, sospecharía que si los efectos de la reputación son reales, se darían a conocer bastante pronto en la historia de un cartel (supongo que si es cierto, estos pueden ser reconsiderados "diste algunas respuestas excelentes, así que ahora voy a upvote todos tus mensajes" en lugar de los efectos de "reputación por puntuación total"). ¿Cómo puedo crear un gráfico que demuestre si esto es cierto, teniendo en cuenta el exceso de puntuación? He pensado que una buena manera de demostrarlo sería ajustando un modelo de la forma
$$Y = \beta_0 + \beta_1(X_1) + \alpha_1(Z_1) + \alpha_2(Z_2) \cdots \alpha_k(Z_k) + \gamma_1(Z_1*X_1) \cdots \gamma_k(Z_k*X_1) + \epsilon $$
donde $Y$ es el score - (mean score per user) (la misma que aparece en los gráficos de dispersión actuales), $X_1$ es el post number y el $Z_1 \cdots Z_k$ son variables ficticias que representan algún rango arbitrario de números de puesto (por ejemplo $Z_1$ es igual a 1 si el número de puesto es 1 through 25 , $Z_2$ es igual a 1 si el número de puesto es 26 through 50 etc.). $\beta_0$ y $\epsilon$ son el gran intercepto y el término de error, respectivamente. Entonces sólo examinaría la estimación de $\gamma$ pendientes para determinar si los efectos de la reputación aparecieron al principio del historial de un cartel (o mostrarlos gráficamente). ¿Es este un enfoque razonable (y apropiado)?
Parece popular ajustar algún tipo de línea de suavización no paramétrica a gráficos de dispersión como estos (como loess o splines), pero mi experimentación con splines no reveló nada esclarecedor (cualquier evidencia de efectos positivos al principio de la historia del póster fue leve y temperamental al número de splines que incluí). Dado que tengo la hipótesis de que los efectos se producen al principio, ¿es mi enfoque de modelización anterior más razonable que los splines?
También hay que tener en cuenta que, aunque he extraído prácticamente todos estos datos, todavía hay muchas otras comunidades que examinar (y algunas, como superuser y serverfault, tienen muestras igualmente grandes de las que sacar provecho), por lo que es muy razonable sugerir en futuros análisis que utilice una muestra retenida para examinar cualquier relación.


{kind=link}